Yong-Ha Lee![]() , Yuna Jeong
, Yuna Jeong![]() , Jong-Hoon Won†
, Jong-Hoon Won†![]()
Autonomous Navigation Lab., Department of Electrical and Computer Engineering, Inha University, Incheon 22212, Korea
†Corresponding Author: Jong-Hoon Won, E-mail: jh.won@inha.ac.kr
Citation: Lee, Y.-H., Jeong, Y., & Won, J.-H. 2026, Augmented Reality LiDAR Point Cloud Fusion for Sim-to-Real Validation of Autonomous Driving Perception, Journal of Positioning, Navigation, and Timing, 15, 45-53.
Journal of Positioning, Navigation, and Timing (J Position Navig Timing) 2026 March, Volume 15, Issue 1, pages 45-53. https://doi.org/10.11003/JPNT.2026.15.1.45
Received on Dec 26, 2025, Revised on Jan 16, 2026, Accepted on Feb 09, 2026, Published on Mar 15, 2026.
Copyright © The Institute of Positioning, Navigation, and Timing
License: Creative Commons Attribution Non-Commercial License (https://creativecommons.org/licenses/by-nc/4.0/) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.
While perception in autonomous driving enables the detection of surrounding objects, such as pedestrians, vehicles, and road infrastructure, inaccuracies in perception algorithms may lead to critical situations, such as critical safety risks. Extensive validation across diverse object classes, repetitive experiments, and rigorous edge-case testing is thus required. Although driving simulators provide scalable and cost-effective testing environments, they are limited in accurately reproducing real vehicle dynamics and are therefore mainly used in the early development stages. This study proposes an augmented-reality LiDAR point cloud system for sim-to-real validation that integrates the advantages of real-world and simulation-based testing. Virtual LiDAR point clouds generated from simulator environments are fused with real-world LiDAR data, enabling the injection of virtual objects into real driving scenarios while preserving real vehicle dynamics and geometry. The implementation includes analysis and integration of point cloud density in both domains for realistic fusion, occlusion modeling of virtual LiDAR point clouds as observed in real environments, and a parallel processing algorithm for real-time data handling. The proposed approach can safely and accurately evaluate perception algorithms by allowing the injection of virtual objects into real-world scenarios, thereby ensuring that vehicle dynamics and geometry are faithfully represented. Furthermore, this method addresses the data-hungry nature of recent AI-based autonomous driving models by leveraging the scalability of simulator-based data augmentation.
autonomous vehicle, LiDAR, augment reality, simulation to reality, verification and validation
자율주행 기술 발전에 따라 국내 외적으로 완전 자율주행 차량이 널리 보급되고 있다. 국내에서는 일부 규제자유 특구 지역에서 자율주행 다목적 차량이 운행 중이며 (Lee 2020), 자율주행 셔틀 또한 운행 중에 있다 (Park et al. 2023). 해외의 경우에는 구글 waymo (Sun et al. 2020), 아마존 (Lee 2022), 중국 (Yu et al. 2017), 일본 (Imai 2019) 등 다양한 국가, 기관, 업체에서 완전 자율주행을 시범 운행 중이다. 자율주행 차량의 보급에 따라 사고율 또한 급격하게 상승하고 있다. 사고 사례에 있어 특히 인지 시스템의 문제는 치명적이다. 인지 시스템은 차량의 주변 객체와 관련한 것으로 충돌과 직접적으로 연관 되어있으며, 대부분의 자율주행 개발사들이 활용하는 모듈 기반 자율주행 시스템에 있어 가장 첫 단계의 모듈이므로 (Tang et al. 2018), 연쇄적으로 다음 모듈에 오차 전파를 일으켜 결론적으로 차량 제어에 문제를 일으키는 원인이 된다. 따라서 자율주행 인지 시스템의 완성도 있는 알고리즘을 구현하기 위해 다양한 노력이 수반되어야 한다.
자율주행 인지 시스템의 검증을 위해서는 다양한 상황에서의 반복적인 실험을 통해 인지 시스템의 오류를 찾아내야 한다. 특히 예상치 못한 edge-case에서의 위험을 제거해야 한다. 이를 위해 여러 도로 구조물, 보행자, 트럭, 버스, 세단, SUV 등 다양한 종류의 객체에 대한 시험을 수행해야 한다 (Fan et al. 2023). 일례로 보행자의 경우만 한정하더라도, 어린이, 남성, 여성, 휠체어, 자전거, 보행기 등 다양한 class가 존재하며, 이를 구조물, 차량으로 확장할 경우 가늠하기 힘들 정도의 class가 존재한다. 실제로 이를 준비하고 실험하는 것은 매우 어렵고 비용, 시간, 노력이 많이 소요된다.
이러한 문제를 해결하기 위해 가상 환경의 이점을 갖는 드라이빙 시뮬레이터를 활용한 자율주행 시스템 시험 검증 방법이 다수 제안되었다. MORAI Sim은 국내 개발 드라이빙 시뮬레이터로써 Light Detection and Ranging (LiDAR), Camera, Radar, GPS/INS 등 다양한 센서를 내재하고 있다. 또한 KCITY, KATRI, 판교 스마트시티 등 다양한 국내 도로 환경을 모사하고 있다 (MORAI Inc. 2025). 해외에서는 CarMaker (IPG Automotive GmbH 2025), VTD (Hexagon 2025), CARLA (CARLA 2025) 등이 자율주행 시험에 주로 사용되고 있다. 이 시뮬레이터들 또한 자율주행에 필요한 센서를 다수 지원한다. 그러나 드라이빙 시뮬레이터는 현가, 타이어, 차량 질량, 차종에 따른 차량의 복잡한 dynamics를 정확히 반영하지 못한다 (Meuleners & Fraser 2015). 특히 다수의 시뮬레이터는 이를 바이시클 모델로 단순화해 차량의 제어까지 이어지는 시험 검증 수행 시 실제 차량과 많은 오차가 발생한다 (Zhang et al. 2024). 이를 해결하고자 가상 객체를 실제 환경에서 활용하고자 하는 AR 포인트 클라우드에 관한 연구는 지속적으로 수행되어왔다. CAD를 통해 보행자, 차량, 도로 구조물을 모델링해 이를 현실 환경 LiDAR 데이터 필드에 배치해 동적 객체를 생성을 수행하는 연구가 수행되었다 (Fang et al. 2020). 그러나 이 방법은 사용자가 3D CAD에 익숙해야 하며, 각각의 객체를 직접 모델링 하는데 많은 노력이 소요되어 확장성 제한이 있다. 다음으로 시뮬레이터를 활용해 포인트 클라우드 AR 객체를 현실에서 활용하고자 하는 연구가 수행되었다 (Genevois et al. 2022). 이 방법은 센서 수준의 AR을 활용해 실제 차량의 LiDAR 데이터에 시뮬레이터 객체를 병합하는 검증 프레임워크를 제안했다.
본 연구에서는 이러한 한계를 극복하기 위해 자율주행 인지 알고리즘에서 널리 쓰이는 LiDAR 센서에 집중한 증강현실 Augment-Reality (AR) 포인트 클라우드 알고리즘을 구현한다. LiDAR 센서는 포인트 클라우드라고 불리는 점 군 데이터를 출력으로 하는 센서이다. 측정한 거리 정보를 기반으로 객체의 속도를 추정할 수 있어 인지 알고리즘에서 널리 쓰이는 센서이다 (Alaba & Ball 2022). 본 연구는 LiDAR 센서의 출력인 포인트 클라우드를 가상 환경에서 취득해 현실 환경에 통합하는 프레임워크를 구현한다. 이는 현실 LiDAR 데이터에 가상 LiDAR 데이터를 주입하는 것으로, 가상-현실을 연계하는 Simulation-to-Reality (Sim2Real) 방법이다.
본 연구에서 Sim2Real이란, 가상 환경에서 생성된 객체를 실제 자율주행 차량의 LiDAR 센서 데이터 수준에서 주입하여, 실제 차량의 동역학, 센서 기하, 실시간 인지 파이프라인을 그대로 유지한 상태로 인지 알고리즘을 검증하는 과정을 의미한다. 즉, 본 연구에서의 Real은 가상 객체의 생성 출처가 아닌, 실제 차량 기반 인지·판단·제어 파이프라인의 실행 환경을 지칭한다.
시뮬레이터의 객체를 현실에서 활용하고자 하는 Genevois et al. (2022)의 개념이 본 연구의 방법과 유사하나, 본 연구에서는 해당 연구에서 확장하지 못한 실제 환경 오버레이와 시각적 정합성 한계를 실제 환경의 포인트 클라우드 배경을 통합해 극복하고자 한다. 또한 해당 연구에서는 각 도메인의 센서 해상도 차이에 따라 10 m 이상의 거리를 가지는 객체에 대해서는 정사각형으로 인식되는 문제가 존재했지만 본 연구에서는 고 해상도 가상 LiDAR를 통합하는 방식을 활용해 이를 해결하고자 한다.
본 논문의 주요 기여는 다음과 같다. 첫째, 실제 자율주행 차량의 LiDAR 센서 데이터 흐름에 가상 객체 포인트 클라우드를 센서 수준에서 주입하는 Sim2Real 기반 AR LiDAR 포인트 클라우드 프레임워크를 제안한다.
둘째, 가상 객체와 실제 배경 포인트 클라우드 간의 물리적으로 일관된 가시성 관계를 유지하기 위해, LiDAR 깊이 버퍼 기반의 실시간 폐색 모델링 알고리즘을 설계하였다.
셋째, 기존 연구에서 한계로 지적된 원거리(10 m 이상) 객체 형상 붕괴 문제를, 고해상도 가상 LiDAR와 병렬 폐색 처리 파이프라인을 통해 개선하고, Density Uniformity (DU) 및 Within-Cluster Variance (WCV) 지표를 통해 정량적으로 검증하였다.
본 논문의 구성은 다음과 같다. 2장에서는 AR 포인트 클라우드 구현을 위한 방법론에 대해 설명한다. 3장에서는 현실과 가상 환경을 융합하여 구현된 제안 시스템의 실시간 처리 성능 및 인지 알고리즘 적용 타당성 검증 실험 결과를 제시하고, 4장에서는 이 연구의 결론 및 향후 연구 방향을 서술한다.
이 연구에서 MORAI Sim은 차량 동역학을 포함한 전체 주행 시뮬레이션 도구로 활용되지 않는다. 대신, 가상 객체(차량, 보행자 등)에 대한 LiDAR 포인트 클라우드와 객체 단위의 Ground-Truth 정보를 생성하기 위한 가상 객체 생성기로 사용된다. 차량의 실제 주행, 센서 장착 위치, 센서 기하 구조 및 동역학은 실제 자율주행 차량을 기준으로 수행되며, 시뮬레이터는 오직 가상 객체 데이터의 공급원으로만 활용된다.
AR LiDAR 포인트 클라우드 시스템은 Mixed-Reality 즉, 혼합 현실 환경을 기반으로 한다. 즉, AR LiDAR 포인트 클라우드 시스템은 가상 환경과 현실 환경을 혼합한 구조로 가상 환경인 드라이빙 시뮬레이터와 현실 환경인 자율주행 차량의 혼합 환경이다. 전체 시스템 아키텍처는 Fig. 1과 같다. 시스템의 혼합 환경을 기반으로 자율주행 차량과 드라이빙 시뮬레이터 환경은 동기화된다. 동기화를 위해 자율주행 차량에 장착된 고정밀 GNSS/INS 장치를 활용한다. GNSS/INS 항법 장치는 MGI-2000 모델로 RTK-fixed된 고정밀 위치 및 방향 정보를 제공한다 (Synerex Inc. 2025). 위치 및 방향 정보는 가상 환경인 드라이빙 시뮬레이터로 Ethernet/LAN을 통한 UDP 통신을 활용해 전송한다. 이 데이터 패킷은 가상 환경 내부의 차량을 현실 환경과 같은 위치 및 방향에 동기화 시킨다. 가상 환경과 현실 환경 간의 혼합 현실 구현을 위한 데이터 통신 및 전체 시스템 구조를 나타낸다. 이를 통해 현실의 자율주행 차량이 드라이빙 시뮬레이터 내부의 객체를 활용할 수 있는 기반이 된다. 이때 GNSS/INS (MGI-2000)는 실제 차량에 장착된 장비로부터 측위 정보를 취득하며, 해당 정보는 가상 환경 내 객체 배치를 위한 참조 좌표계 동기화에만 사용된다. 또한 본 논문에서 사용되는 포인트 클라우드 퓨전은 서로 다른 센서 간의 확률적 결합을 의미하는 일반적인 의미가 아니라, 실제 LiDAR 포인트 클라우드 공간에 가상 객체 포인트 클라우드를 기하적으로 일관되게 통합하는 센서 수준의 공간적 결합을 의미한다.
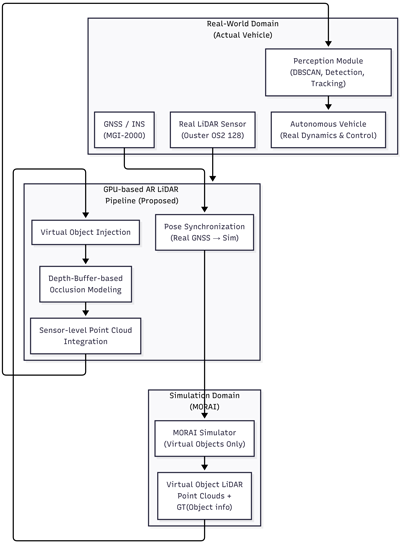
Fig. 1. Overall system architecture of the proposed Sim-to-Real AR LiDAR framework. Virtual objects are generated in the simulator and injected at the LiDAR sensor level into the real vehicle perception pipeline, while real vehicle dynamics, sensor geometry, and real-time processing are preserved.
포인트 클라우드는 LiDAR 센서의 데이터로 주변 환경 정보를 점군 형태로 제공한다. 각각의 포인트는 거리, 위치, 강도 정보를 포함하고 있다. 이를 통해 자율주행 차량은 자차 측위, 객체 인지 등의 과업을 수행한다. 본 연구에서는 이러한 특성 중 객체 인지에 집중한 AR포인트 클라우드 알고리즘을 구현한다. 이를 위해 드라이빙 시뮬레이터 내부의 객체에 대한 포인트 클라우드 만을 실제 자율주행 차량의 LiDAR 포인트 클라우드 공간에 통합한다. 통합을 위해 가상 객체에 대해 시뮬레이터에서 제공하는 객체에 대한 Ground-Truth (GT) 정보를 사용한다. MORAI Sim의 포인트 클라우드는 instance 모드를 활용할 경우 각각의 포인트에 대한 객체 유무를 분류하는 타입을 출력할 수 있다.
본 논문에서 활용한 23.R1.0 버전의 instance segmentation label은 객체의 구분 없이 배치한 순서부터 1부터 순차적으로 할당된다. Vehicle, pedestrian, obstacle 이외의 객체는 할당 값이 존재하지 않아 이 GT 데이터를 통해 객체의 포인트 클라우드 만을 추출할 수 있다. Instance segmentation 데이터는 포인트 클라우드 데이터 필드에서 각각 4 바이트의 X, Y, Z 뒤 4 바이트 필드에 존재한다. 위와 같이 취득한 객체의 포인트 클라우드는 데이터 패킷 형태로 실제 자율주행 제어기로 전송된다. 이후 가상 객체에 대한 포인트 클라우드는 실제 포인트 클라우드 공간에 통합되기 이전에 LiDAR 센서의 특성인 occlusion을 부여한다. 이는 앞선 물체에 LiDAR 센서의 직진하는 빛이 반사되어 뒤에 있는 물체나 공간이 폐색되는 현상이다. 구현을 위해 ray-tracing을 통해 빛의 직진 특성을 모사해 AR 포인트 클라우드에 의해 가려진 실제 포인트 클라우드를 폐색 처리한다. 이를 통해 더욱 사실적인 AR 포인트 클라우드 적용이 가능하다.
파이프라인을 거친 AR 포인트 클라우드 객체는 실제 환경에 통합된다. 이를 통해 가상의 LiDAR 포인트 클라우드 객체를 활용한 Sim2Real 시험을 가능케한다. Fig. 2는 본 논문의 포인트 클라우드 AR 결과를 나타낸다. 가상의 객체는 시뮬레이터 상에서 생성되어 청록색 포인트 클라우드 형태로 실제 LiDAR 데이터와 통합됨을 확인할 수 있다. 녹색 포인트 클라우드는 실제 128 채널 LiDAR로 취득한 포인트 클라우드이며, 적색 포인트 클라우드는 두 도메인의 퓨전에 따라 폐색된 포인트 클라우드를 의미한다.

Fig. 2. Sim-to-Real AR point cloud integration, where simulator-generated object point clouds (blue) are injected into real-vehicle LiDAR measurements (green) after GNSS/INS-based pose synchronization.
고 채널 mechanical 타입 LiDAR 센서는 전방위 데이터를 높은 해상도로 전달하지만 그 데이터의 크기가 매우 큰 특성이 있다. AR 기술을 활용한 가상 포인트 클라우드 데이터는 실제와의 즉각적인 상호작용을 위해 극도로 낮은 지연 시간을 요구한다. 하지만 CPU기반의 전통적인 방식을 이용할 경우 병목현상을 일으켜 데이터 지연이 발생한다. 본 논문에서는 이 문제를 해결하기 위해 포인트 클라우드 데이터를 수신 직후 GPU로 원시 데이터를 전송하고 NVIDIA CUDA (NVIDIA 2025)를 이용해 대규모 병렬 처리를 수행하는 파이프라인을 적용한다. 이 파이프라인은 LiDAR의 복잡한 좌표 변환과 AR 표출에 필요한 객체 포인트만을 식별하는 필터링 작업을 GPU상에서 동시에 처리한다. 이를 통해 CPU의 부하를 최소화하고 종단간 지연 시간을 단축시킨다.
MORAI Sim은 128 채널 VLS-128 LiDAR 데이터를 약 1206 바이트 크기의 UDP 패킷으로 나누어 지속적으로 전송한다. 수신 모듈은 이 패킷들을 비동기적으로 수신하여 하나의 완전한 프레임이 될 때까지 버퍼에 축적한다. VLS-128의 경우, 패킷 헤더의 azimuth 정보를 모니터링하여 특정 방위각을 기준으로 프레임의 시작과 끝을 감지하고 프레임을 분리한다. 완성된 원시 프레임 버퍼는 즉시 GPU 메모리로 복사된다. GPU로 전송된 버퍼는 포인트 데이터 블록으로 취급되며, CUDA kernel은 각 포인트에 대해 동시에 다음 연산을 수행한다. 1) Distance, azimuth 추출, 2) GPU 메모리에 미리 저장된 LiDAR 보정 값(vertical/horizontal angles) 적용, 3) 삼각함수 연산을 통한 spherical 좌표계로부터 cartesian 좌표계로의 변환, 4) 객체 포인트 추출을 위한 instance segmentation 연산. 위 연산을 통해 객체 포인트 클라우드는 필터링 되어 CPU 메모리로 다시 복사된 이후 실제 포인트 클라우드 영역으로 송신한다. CUDA 커널 내 분기문에 따른 성능 저하를 최소화하기 위해, 객체 판별 및 폐색 연산은 조건 분기 대신 마스크 기반 연산으로 구성하여 실행의 일관성을 유지하도록 설계하였다.
가상 객체를 실제 환경 위에 시각화할 때, 객체가 배경 포인트 클라우드를 가리는 폐색 효과는 현실감을 결정하는 핵심 요소이다. 만약 객체보다 뒤에 위치한 배경 포인트가 객체를 통과해 보인다면 사용자는 시각적 이질감을 느끼게 되며, 인지 알고리즘에서 문제가 발생할 수 있다. 본 연구에서는 이러한 문제를 해결하기 위해 GPU 상에서 병렬로 수행되는 2차원 깊이 버퍼 기반 알고리즘을 구현하여 실시간 폐색 필터링을 수행하였다.
제안된 방법은 LiDAR 센서의 원점을 기준으로 모든 3차원 포인트(x,y,z)를 구면 좌표계상의 2차원 격자로 투영하는 원리를 기반으로 한다. 각 포인트는 원점으로부터의 거리, 방위각, 고도각으로 변환되며, 방위각과 고도각은 미리 정의된 해상도에 맞춰 2차원 격자 인덱스(u,v)로 정규화된다. 각 격자 셀은 특정 방향을 의미하며, 해당 방향에서 감지된 포인트 중 가장 가까운 포인트의 깊이 값만을 저장한다. 이와 같이 3차원 공간 정보를 2차원 깊이 이미지로 변환함으로써, 해당 이미지는 LiDAR 기반의 깊이 버퍼로 활용된다. 매 프레임마다 시뮬레이터로부터 동적 객체의 포인트 클라우드가 수신되면, GPU에서 병렬적으로 다음과 같은 실시간 폐색 판별 파이프라인이 수행된다.
첫째, 수신된 객체 포인트를 GPU 메모리로 전송한다. 둘째 객체 포인트를 깊이 값과 2차원 격자 인덱스로 변환하고 초기화된 2048×128 크기의 깊이 버퍼에 대해 동일한 방향에 속한 포인트 중 가장 가까운 깊이 값만을 해당 셀에 기록한다. 셋째, LiDAR 데이터의 sparsity로 인해 포인트가 존재하지 않는 셀이 발생하므로, 1차원 수평 최소값 필터를 적용한다. 이를 통해 인접 픽셀 간의 최소 깊이 값으로 갱신하여, 객체 포인트 간의 빈 공간을 보완하고 연속적인 깊이 마스크를 형성한다. 이후 GPU에는 전처리된 배경 포인트의 격자 인덱스 및 깊이와 홀 필링을 완료한 객체 깊이 버퍼가 동시에 존재하게 된다. 시스템은 각 배경 포인트의 방향에 해당하는 객체의 최소 깊이 값을 조회하고, 깊이 비교를 통해 폐색 여부를 판별한다. 비교 연산은 수백만 개의 배경 포인트에 대해 GPU에서 병렬로 수행되며, 각 포인트의 폐색 여부를 나타내는 Boolean 플래그가 생성된다. 이후 해당 결과만 CPU로 전송되어, Open3D 시각화 모듈에서 폐색된 배경 포인트의 색상을 붉은색으로 표시함으로써 사용자는 객체-배경 간 폐색 관계를 직관적으로 확인할 수 있다. 가상 객체의 투영 인덱스는 사전에 계산 가능하나, LiDAR 폐색 판별은 객체 포인트와 동일한 방향에 존재하는 모든 배경 포인트와의 깊이 비교를 필요로 한다. 따라서 객체 포인트 일부만을 대상으로 하는 방식은 물리적으로 정확한 폐색 판단이 어려우며, 수백만 개의 배경 포인트에 대한 병렬 비교가 가능한 GPU 기반 전체 프레임 처리 방식이 필수적이다.
GPU-CUDA를 활용한 포인트 클라우드 AR 병렬처리 방식의 성능을 검증하기 위해 동일한 로직을 CPU를 활용해 최적화한 CPU-Numba 방식과 비교한다. 실험 환경은 Table 1과 같다. 측정 지표는 1개 프레임의 약 24만개의 포인트를 수신하여 파싱, 좌표 변환, 필터링을 완료하는 데 소요되는 평균 처리 시간(ms)으로 설정한다. 가상의 AR 포인트 클라우드 객체는 시뮬레이터의 확장성에 따른 이점을 반영하고자 혼재한 도로 상황을 가정한다. 실험은 2대의 SUV, 3대의 SUV, 2명의 보행자와 1대의 대형 버스가 혼재한 환경을 가정해 총 세가지 상황의 case-study를 수행한다.
Table 1. Experiment setting.
| Category | Contents |
|---|---|
| GPU | NVIDIA RTX 4080 SUPER |
| CPU | 12th Gen Intel(R) Core i7-12700KF |
| OS | Windows 11 |
| Programming language | Python |
| Deep-learning framework | TensorFlow 2.13.0 |
| GPU accelerate environment | CUDA 11.8, cuDNN 8.6 |
| Simulation environment | MORAI simulator |
실험 결과, 제안된 GPU-CUDA 병렬 처리 아키텍처는 최적화된 CPU-Numba 방식 대비 프레임당 평균 3.66 ms 단축된 처리 속도를 기록하며 우수한 연산 성능을 입증하였다. Fig. 3에 나타낸 각 방법의 성능 지표와 같이, 도로 환경 내 객체 밀도가 높아져 처리해야 할 포인트 클라우드 데이터양이 증가함에 따라 CPU 기반 방식의 연산 부하는 선형적으로 급증하는 경향을 보였다. 반면, 제안된 GPU-CUDA 방식은 고부하 상황에서도 안정적인 처리 속도를 유지함으로써 시스템의 시간적 여유를 확보하였다. 이러한 연산 효율성은 AR 클라이언트 전송 과정에서 발생할 수 있는 네트워크 지연 및 운영체제 오버헤드를 상쇄하기에 충분한 수준으로 판단된다. 결론적으로 본 실험은 GPU-CUDA 기반의 병렬 처리 시스템이 Sim2Real을 위한 LiDAR AR 환경의 실시간성을 준수하는 데 있어 효과적임을 나타낸다.
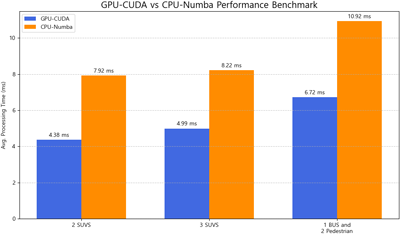
Fig. 3. Performance comparison of GPU-CUDA parallel processing and CPU-Numba processing for AR point clouds, demonstrating faster frame processing on GPU as object number increases.
제안하는 AR 포인트 클라우드 시스템의 현실 적용 가능성을 평가하기 위해, 실제 LiDAR 기반 객체 인지 파이프라인에서 널리 사용되는 Density-Based Spatial Clustering of Applications with Noise (DBSCAN) 클러스터링 알고리즘을 적용한 검증 실험을 수행하였다. 실험에서는 시뮬레이터 내에서 생성된 AR 객체 포인트 클라우드를 인지 모듈의 입력으로 사용하고, 실제 주행 환경에서 객체 인식에 사용되는 DBSCAN 파라미터와 동일한 설정값을 적용하였다.
Fig. 4는 AR 포인트 클라우드에 대한 DBSCAN 클러스터링 시각화 결과를 나타낸다. 그림에서 볼 수 있듯이, AR 객체는 배경 노이즈와 명확히 구분되어 단일 클러스터로 성공적으로 군집화 되었으며, 객체 윤곽을 따라 포인트가 밀집된 형태를 보여 실제 LiDAR 데이터와 유사한 군집 구조를 형성함을 확인할 수 있다. 본 실험에서는 실제 LiDAR 사용 시와 동일한 파라미터를 적용한 raw DBSCAN을 사용함으로써, 제안한 AR 방식의 가상 LiDAR 포인트 클라우드가 기존 인지 파이프라인에 별도의 조정 없이 적용 가능한지를 평가하였다.

Fig. 4. Visualization of DBSCAN clustering on AR point clouds. The AR object is successfully clustered as a single entity, clearly separated from noise, with point distributions closely following the object contours, resembling real LiDAR clusters.
정성적 시각화에 더해, DBSCAN 기반 객체 클러스터의 형상 안정성을 정량적으로 평가하기 위해 다수 프레임에 대해 3D IoU를 산출하였다. Fig. 5는 총 200 프레임에 대해 단일 객체 환경과 다중 객체 환경(1 bus, 2 SUVs)에서의 3D IoU 변화를 나타낸다. 본 논문은 인지 성능을 강화하기 위한 논문이 아니라 가상 포인트 클라우드를 실제 환경에 적용하기 위해 raw DBSCAN을 실험 수단으로 이용하므로 산출된 IoU 값은 절대적으로 매우 높은 수치는 아니나, 모든 실험 조건에서 다수 프레임에 걸쳐 평균적으로 0.5 내외의 값을 안정적으로 유지하였다. 특히 다중 객체 환경에서도 IoU의 급격한 붕괴 없이 비교적 낮은 분산을 보이며 유지되는 경향을 확인할 수 있었는데, 이는 제안한 깊이 버퍼 기반 폐색 모델링이 객체 간 상호 폐색 및 배경 포인트 혼입을 효과적으로 억제함으로써 클러스터 형상의 시간적 일관성을 유지하는 데 기여함을 시사한다. 이러한 결과는 제안하는 AR 포인트 클라우드 시스템이 실제 LiDAR 기반 인지 파이프라인에서 객체 군집 및 형상 분석 단계에 실질적으로 활용 가능함을 정량적으로 뒷받침한다.
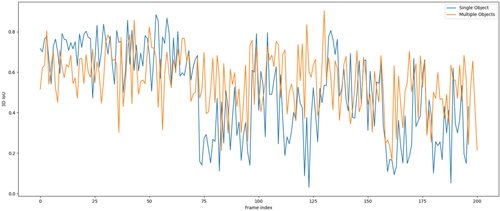
Fig. 5. Temporal evolution of 3D IoU over the first 200 frames. Both scenarios are evaluated over the same frame range to ensure a fair comparison.
AR 포인트 클라우드에서의 원거리 객체 포인트 희소성 문제는 기존 연구 (Genevois et al. 2022)에서 10 m 이상 거리에서 객체 형상 손실로 보고된 바 있다. 본 연구에서는 이러한 한계를 극복하기 위해 128 채널 고해상도 Virtual LiDAR와 CUDA 기반 병렬 폐색 최적화 알고리즘을 적용하였다. 이를 통해 원거리에서도 객체 형상을 안정적으로 유지할 수 있는 AR 포인트 클라우드 파이프라인을 설계하였다.
실시간 처리 성능은 객체 거리와 포인트 수에 따라 평가하였다. Fig. 6은 객체 거리별 프레임 처리 시간을 나타낸다. 실험 결과, 객체와의 거리에 따른 프레임 처리 시간은 큰 변화폭 없이 평균 0.022 s에서 0.032 s 사이로 안정적인 결과를 보였다. 이는 CUDA 기반 병렬 처리와 최적화된 포인트 클라우드 폐색 알고리즘 덕분에, 고해상도 AR 포인트 클라우드에서도 30 Hz 이하의 포인트 클라우드 실시간 처리 요건을 충족함을 의미한다.
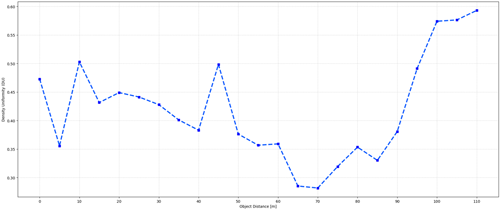
Fig. 6. Long-range fidelity, Density Uniformity (DU) evaluation of AR point clouds. The system maintains object shape stability beyond 10 m up to 110 m, showing consistent clustering despite distance and viewing angle variations.
검증을 위해 승용 차량 객체를 10 m 이상의 다양한 거리 구간에 배치하고, 실제 자차 주행 환경에서 AR 객체 포인트 클라우드를 수집하였다. 객체 형상 유지 성능을 정량적으로 평가하기 위해 다음과 같은 지표를 사용하였다. WCV는 클러스터 내 포인트의 중심 응집도를 나타내며, 값이 낮을수록 객체 형상에 따라 포인트가 밀집되어 있음을 의미한다. DU는 클러스터 중심으로부터의 거리 분포 표준편차로 정의되며, 포인트 밀도의 균일성을 정량화 한다.
Fig. 7의 DU 분석 결과를 살펴보면, 기존 연구에서 한계로 지적된 10 m를 넘어 최대 110 m 거리까지 객체 형상이 유지됨을 확인할 수 있다. 거리 증가 및 주행 각도 변화에 따라 일부 밀도 편차가 관찰되었으나, 전 거리 구간에서 DU 기반 검출과 클러스터링은 안정적으로 수행되었다. 이는 고해상도 Virtual LiDAR를 통해 원거리에서도 최소한의 포인트 밀도를 확보하고, 병렬 폐색 처리로 배경 포인트 혼입을 억제한 결과로 해석된다. 한편 Figs. 4와 5에서 관찰되는 바와 같이, 중·원거리 구간에 비해 근거리 구간에서는 DU 및 WCV 지표의 변화가 직관적으로 단조롭지 않게 나타난다. 이러한 현상은 제안 알고리즘의 구조적 한계라기 보다는, 실제 LiDAR 센서의 관측 특성과 근거리 환경 요인에 기인한 결과로 해석할 수 있다. 근거리에서는 LiDAR 빔 밀도가 급격히 증가함에 따라 객체 표면의 미세한 기하 구조, 반사 특성, 그리고 주행 중 상대적 자세 변화가 포인트 분포에 과도하게 반영된다. 이로 인해 포인트 수는 충분히 확보되지만, 국부적인 밀도 편차가 확대되어 DU 및 WCV 값이 상대적으로 불안정하게 나타날 수 있다 (Petras et al. 2023).
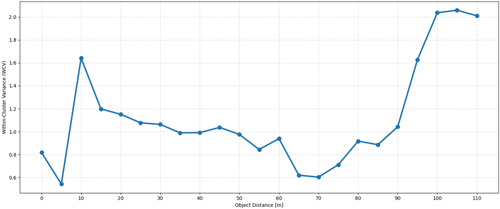
Fig. 7. Within-Cluster Variance (WCV) analysis for long-range AR point clouds. WCV remains low and stable beyond 50 m, demonstrating effective point density retention through 128-channel high-resolution virtual LiDAR and CUDA-based occlusion optimization.
반면 중·원거리 구간에서는 포인트 밀도가 감소함에도 불구하고, 제안한 깊이 버퍼 기반 폐색 모델링을 통해 객체 외부 포인트의 혼입이 효과적으로 억제된다. Fig. 8의 WCV 분석 결과에서도 50 m 이상 거리에서 값이 급격히 증가하지 않고 비교적 낮은 수준으로 안정화됨을 확인할 수 있다. 90 m 이상에서는 거리 증가에 따른 포인트 희소성으로 인해 WCV가 증가하는 경향이 나타나지만, 최대 110 m까지 객체 검출과 클러스터 응집도는 유지되었다. 이러한 결과는 제안한 AR 포인트 클라우드 시스템이 단순히 포인트 수 증가에 의존하는 것이 아니라, 실제 LiDAR 관측 특성을 고려한 폐색 처리와 병렬 처리 구조를 통해 중·원거리 환경에서도 객체 형상의 구조적 일관성을 유지하도록 설계되었음을 보여준다.
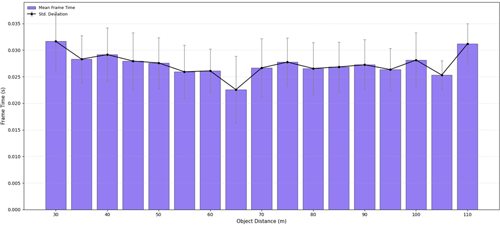
Fig. 8. Frame processing time versus object distance. Processing time remains stable between 0.022 s and 0.032 s, corresponding to real-time performance of ~30 Hz, enabled by parallel CUDA processing and optimized point cloud occlusion algorithms.
본 논문은 실제 LiDAR 기반 자율주행 인지 시스템에서 AR 포인트 클라우드의 Sim2Real 적용 가능성을 검증했다. 제안된 시스템은 실제 주행 환경에서 수집된 LiDAR 포인트 클라우드와 시뮬레이터에서 생성된 가상 객체 포인트를 융합함으로써, 현실성 있는 혼합 데이터 생성을 가능하게 하였다. 특히, 이전 연구에서 한계점으로 지적된 센서 해상도 차이에 따른 원거리 객체 인식 왜곡 문제, 즉 객체가 정사각형 형태로 단순화되는 현상을 고해상도 LiDAR 센서 적용을 통해 개선하였다.
검증을 위해 LiDAR 인지 과정에서 널리 사용되는 DBSCAN 클러스터링 알고리즘을 동일한 조건에서 적용하였으며, 실제 데이터와 AR 데이터 간의 군집 형태, 밀도 분포, 통계적 일관성을 비교하였다. 결과적으로, AR 포인트 클라우드는 객체의 거리에 따라 포인트 클라우드의 구조적 특성을 잃지 않았으며, WCV, DU 등 포인트 클라우드 밀도와 관련한 수치적 지표를 통해 검증되었다. 특히 10 m 이상의 먼 거리에 대한 객체의 구조적 특성을 잃지 않는 결과를 도출했다. 이러한 결과는 제안된 AR 포인트 클라우드가 실제 인지 알고리즘에 직접 활용될 수 있는 수준의 공간적 일관성과 통계적 신뢰성을 확보하였음을 의미한다. 향후 연구에서는 이를 활용해 실제 차량의 제어까지 포함한 closed-loop 자율주행 검증 환경으로 확장함으로써, AR 객체가 차량의 인지–판단–제어 파이프라인 전반에 미치는 영향을 정량적으로 평가하고, AR 기반 Vehicle-in-the-Loop 플랫폼의 실차 적용 가능성을 검증할 예정이다.
본 연구는 교육부 및 한국연구재단의 “첨단분야 혁신융합대학사업 사업비”를 지원받아 일부 수행되었습니다.
Conceptualization, Y.-H. Lee, Y. Jeong, and J.-H. Won; methodology, Y.-H. Lee, Y. Jeong, and J.-H. Won; software, Y.-H. Lee and Y. Jeong; validation, Y.-H. Lee, Y. Jeong, and J.-H. Won; formal analysis, Y.-H. Lee, Y. Jeong, and J.-H. Won; investigation, Y.-H. Lee and Y. Jeong; resources, J.-H. Won; data curation, Y.-H. Lee; writing—original draft preparation, Y.-H. Lee; writing—review and editing, J.-H. Won; visualization, Y.-H. Lee; supervision, J.-H. Won; project administration, J.-H. Won; funding acquisition, J.-H. Won.
The authors declare no conflict of interest.
Alaba, S. Y. & Ball, J. E. 2022, A survey on deep-learning-based lidar 3d object detection for autonomous driving, Sensors, 22, 9577. https://doi.org/10.3390/s22249577
CARLA Simulator 2025, CARLA – Open-source simulator for autonomous driving research [Internet], cited 2025 Nov 13. https://carla.org/
Fan, R., Guo, S., & Bocus, M. J. 2023, Autonomous driving perception (Cham, Switzerland: Springer). https://doi.org/10.1007/978-981-99-4287-9
Fang, J., Zhou, D., Yan, F., Zhao, T., Zhang, F., et al. 2020, Augmented LiDAR simulator for autonomous driving, IEEE Robotics and Automation Letters, 5, 1931-1938. https://doi.org/10.1109/LRA.2020.2969927
Genevois, T., Horel, J. B., Renzaglia, A., & Laugier, C. 2022, Augmented reality on lidar data: Going beyond vehicle-in-the-loop for automotive software validation, IEEE IV 2022, pp.971-976. https://doi.org/10.1109/IV51971.2022.9827351
Hexagon 2025, Virtual Test Drive | Hexagon [Internet], cited 2025 Nov 13. https://hexagon.com/products/virtual-test-drive
Imai, T. 2019, Legal regulation of autonomous driving technology: Current conditions and issues in Japan, IATSS research, 43, 263-267. https://doi.org/10.1016/j.iatssr.2019.11.009
IPG Automotive GmbH. 2025, CarMaker – The simulation solution for virtual test driving [Internet], cited 2025 Nov 13. https://www.ipg-automotive.com/en/products-solutions/software/carmaker/
Lee, J. 2022, Amazon-owned self driving firm Zoox seeks to test robotaxi in California – REUTERS [Internet], cited 2022 Sep 8. https://www.reuters.com/business/autos-transportation/amazon-owned-self-driving-firm-zoox-seeks-test-robotaxi-california-2022-07-19/
Lee, J.-H. 2020, A Study on the Legal Improvement for Autonomous Vehicle Testing on BRT Roads, Journal of Science & Technology Law, 26, 169-202. http://doi.org/10.32430/ilst.2020.26.3.169
Meuleners, L. & Fraser, M. 2015, A validation study of driving errors using a driving simulator, Transportation Research part F, 29, 14-21. https://doi.org/10.1016/j.trf.2014.11.009
MORAI Inc. 2025, MORAI Digital Twin Simulation for Autonomous Systems [Internet], cited 2025 Nov 13. https://www.morai.ai/
NVIDIA Corporation. 2025, CUDA C Programming Guide [Internet], cited 2025 Oct 28. https://docs.nvidia.com/cuda/cuda-c-programming-guide/
Park, H., Jeong, S., Jung, D., Kim, Y., & Kim, M. 2023, Design of 4WS Lateral Controller for Low-speed Self-driving Shuttle, in KSAE Annual Conference, Ulsan, Korea, 15 Nov 2023, pp.1700-1705.
Petras, V., Petrasova, A., McCarter, J. B., Mitasova, H., & Meentemeyer, R. K. 2023, Point density variations in airborne LiDAR point clouds, Sensors, 23, 1593. https://doi.org/10.3390/s23031593
Sun, P., Kretzschmar, H., Dotiwalla, X., Chouard, A., Patnaik, V., et al. 2020, Scalability in perception for autonomous driving: Waymo open dataset, CVPR 2020, pp.2446-2454. https://doi.org/10.1109/CVPR42600.2020.00252
Synerex Inc. 2025, MGI-2000 | SYNEREX [Internet], cited 2025 Oct 28. https://www.synerex.kr/mgi-2000
Tang, J., Shaoshan, L., Pei, S., Zuckerman, S., Chen, L., et al. 2018, Teaching autonomous driving using a modular and integrated approach, IEEE COMPSAC 2018, pp.361-366. https://doi.org/10.1109/COMPSAC.2018.00057
Yu, H., Yang, S., Gu, W., & Zhang, S. 2017, Baidu driving dataset and end-to-end reactive control model, IEEE IV 2017, pp.341-346. https://doi.org/10.1109/IVS.2017.7995742
Zhang, T., Sun, Y., Wang, Y., Li, B., Tian, Y., et al. 2024, A survey of vehicle dynamics modeling methods for autonomous racing, IEEE Transactions on Intelligent Vehicles, 9, 4312-4334. https://doi.org/10.1109/TIV.2024.3351131